Sampling
FMB819: R을 이용한 데이터분석
Today’s Agenda
샘플링, 샘플링 변동성, 샘플링 분포 개념을 익히기.
샘플링 용어:
- 모집단 (Population)
- 표본 (Sample)
- 모수 (Population Parameter)
- 점 추정치 또는 표본 통계량 (Point Estimate or Sample Statistic)
불편추정량 (Unbiased Estimator)의 정의.
통계적 추론의 핵심 정리: 중심극한정리 (Central Limit Theorem, CLT).
왜 표본 추출을 배우는가?
경영 현장에서 전수 조사는 대부분 불가능하거나 비용이 너무 큼.
| 상황 | 알고 싶은 것 | 현실적 방법 |
|---|---|---|
| 신제품 출시 전 | 전체 고객의 구매 의향 | 소비자 설문 조사 (표본) |
| 신용 리스크 평가 | 전체 대출자의 부도율 | 과거 데이터 표본 분석 |
| 투자 전략 수립 | 시장 전체의 수익률 분포 | 주식 표본으로 백테스트 |
| 품질 관리 | 전체 생산품의 불량률 | 샘플링 검사 |
| 컨설팅 실사 (Due Diligence) | 기업 재무 전반 | 계정 표본 감사 |
핵심 질문: 표본에서 얻은 숫자를 얼마나 믿을 수 있는가?
초록색 파스타의 비율은 얼마일까?

- 모든 초록색 파스타를 세는 것은 너무 힘듦! 😩 다른 방법은?
표본 추출 (Sampling)
파스타 20개를 표본으로 선택함.
무작위(random) 로 선택되었음.
결과는 다음과 같음.
| 색상 | 개수 | 비율 |
|---|---|---|
| 초록색 | 14 | 0.70 |
| 빨간색 | 5 | 0.25 |
| 노란색 | 1 | 0.05 |
- 0.70 값은 전체 그릇에서 초록색 파스타의 비율을 추정하는 값으로 볼 수 있음.

표본 변동성 (Sampling Variation)
만약 새로운 표본을 추출한다면 (이전에 뽑은 20개의 파스타를 다시 그릇에 넣고)? 이전처럼 녹색 파스타 14개가 나올까?
아마 아닐 것임. 표본은 추출할 때마다 달라질 것임.
핵심 포인트: 표본은 무작위로 추출.
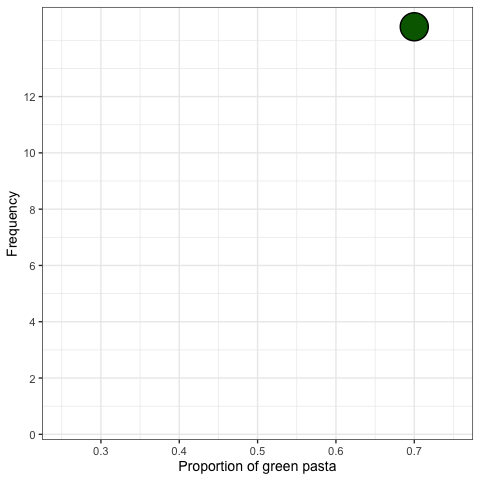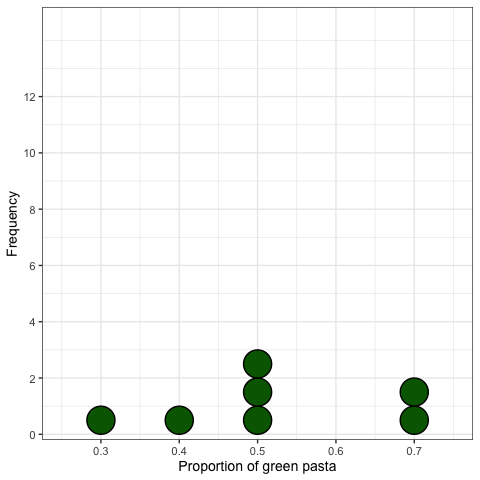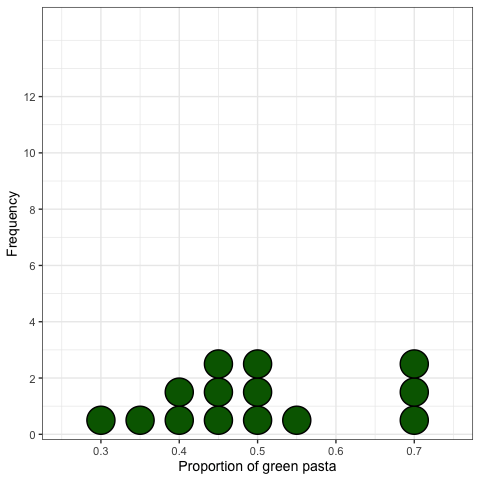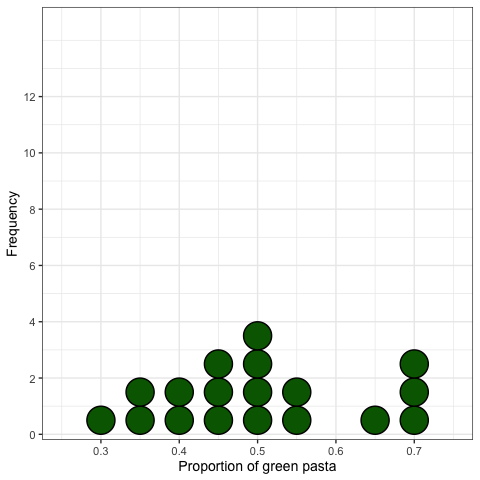
18개의 표본 추출
20개의 파스타를 복원 추출하여 18개의 표본을 뽑아 보면
각각의 표본은 다음과 같음:
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
18개의 표본 추출
20개의 파스타를 복원 추출하여 18개의 표본을 뽑아 보면
각각의 표본은 다음과 같음:
| 표본 번호 | 개수 | 비율 |
|---|---|---|
| 1 | 14 | 0.70 |
| 2 | 14 | 0.70 |
| 3 | 10 | 0.50 |
| 4 | 10 | 0.50 |
| 5 | 6 | 0.30 |
| 6 | 10 | 0.50 |
| 7 | 8 | 0.40 |
| 8 | 9 | 0.45 |
| 9 | 11 | 0.55 |
| 표본 번호 | 개수 | 비율 |
|---|---|---|
| 10 | 8 | 0.40 |
| 11 | 7 | 0.35 |
| 12 | 9 | 0.45 |
| 13 | 9 | 0.45 |
| 14 | 14 | 0.70 |
| 15 | 11 | 0.55 |
| 16 | 10 | 0.50 |
| 17 | 7 | 0.35 |
| 18 | 13 | 0.65 |
Task 1
- 이전 슬라이드에서 녹색 파스타 비율을 포함하는
data.frame을 생성하시오. 이 데이터 프레임의 이름을pasta로 지정하고, 비율을 포함하는 변수를prop_green으로 설정하시오.
ggplot2를 사용하여 이 비율의 히스토그램을 생성하시오.
geom_histogram()함수에서 다음 매개변수를 사용하시오:
boundary = 0.325, binwidth = 0.05.
표본 분포 (Sampling distribution): 히스토그램

표본 추출 실험: 정리
표본 추출이라는 통계 개념을 실험함.
목표: 녹색 파스타의 비율을 알고자 함.
방법:
전수 조사(Census): 시간이 많이 걸리고, 많은 경우 매우 비용이 많이 듦.
표본 추출(Sampling): 그릇에서 20개의 파스타를 무작위로 뽑아 추정값을 얻음.
첫 번째 추정값은 0.70이었지만, 이는 대부분의 다른 추정값보다 높았음.
중요: 각 표본은 무작위로 추출됨 → 표본이 서로 다름! → 추출된 비율이 달라짐 → 표본 변동성(Sampling Variation)
가상의 표본 추출하기 (실제 표본 아님)
- 그릇 안의 녹색, 빨간색, 노란색 파스타 개수를 정확히 셈.
- 그릇 안의 모든 파스타 데이터 다운로드
가상 삽을 사용하여 한 번 표본 추출
moderndive패키지의rep_sample_n함수를 사용하여 크기 50의 첫 번째 표본을 추출.
## # A tibble: 6 × 3
## # Groups: replicate [1]
## replicate pasta_ID color
## <int> <int> <chr>
## 1 1 284 green
## 2 1 101 green
## 3 1 623 yellow
## 4 1 645 green
## 5 1 400 red
## 6 1 98 yellow- replicate 열은 표본의 ID를 나타냄. 여기서는 1.
초록색 파스타 비율 계산
## # A tibble: 1 × 4
## replicate num_green sample_n prop_green
## <int> <int> <int> <dbl>
## 1 1 23 50 0.46- 다음을 계산:
- 표본 내 초록색 파스타 개수
- 표본 내 전체 관측값 개수 (여기서는 50)
- 초록색 파스타 비율 계산
- 초록색 파스타 비율은 0.46! 이것은 초록색 파스타 비율의 추정치(estimate)임. 한 번 더 해보면 어떨까?
- 만약 여러 번, 예를 들어 33번 시도하면 어떻게 될까?
가상 삽을 33번 사용하기
- 33개의 크기 50인 표본을 생성.
## # A tibble: 1,650 × 3
## # Groups: replicate [33]
## replicate pasta_ID color
## <int> <int> <chr>
## 1 1 495 yellow
## 2 1 534 green
## 3 1 297 yellow
## 4 1 208 green
## 5 1 131 green
## 6 1 569 red
## 7 1 522 yellow
## 8 1 248 green
## 9 1 365 red
## 10 1 665 yellow
## # ℹ 1,640 more rows- 각 표본에서 초록색 파스타의 비율을 계산.
## # A tibble: 33 × 4
## replicate num_green sample_n prop_green
## <int> <int> <int> <dbl>
## 1 1 24 50 0.48
## 2 2 25 50 0.5
## 3 3 27 50 0.54
## 4 4 23 50 0.46
## 5 5 25 50 0.5
## 6 6 22 50 0.44
## 7 7 18 50 0.36
## 8 8 30 50 0.6
## 9 9 29 50 0.58
## 10 10 18 50 0.36
## # ℹ 23 more rows(가상!) 표본 변동성
실제 실험처럼 가상 샘플도 무작위 표본을 생성함.
virtual_prop_green데이터 프레임의prop_green열은 표본마다 값이 다름.다시 말해, 표본 분포를 시각화할 수 있음:
ggplot(virtual_prop_green, aes(x = prop_green)) +
geom_histogram(binwidth = 0.02,
boundary = 0.51,
color = "white",
fill = "darkgreen") +
scale_y_continuous(breaks = seq(0, 12, by = 2)) +
labs(x = "Proportion of 50 pasta that were green",
y = "Frequency",
title = "Distribution of 33 samples of size 50") +
theme_bw(base_size = 20)
Task 2
33개의 표본만 추출하는 대신, 이번에는 1000개를 추출해보자!
- 데이터를 불러와
pasta객체에 저장하시오.
moderndive패키지의rep_sample_n()함수를 사용하여 크기 50인 표본을 1000개 생성하라.각 표본에서 초록색 파스타의 비율을 계산하라. (
group_by()+summarize()+mutate()파이프라인 활용)각 표본에서 얻은 초록색 파스타 비율의 히스토그램을 그리시오.
무엇을 관찰할 수 있는가? 어떤 비율이 가장 자주 발생하는가? 33개의 표본을 사용할 때와 비교하여 히스토그램의 모양이 어떻게 달라지는가?
추출한 50개의 파스타 중 초록색 파스타가 20% 미만일 확률은 얼마나 되는가?
- 힌트:
mean(virtual_prop_green$prop_green < 0.20)로 계산 가능.
- 힌트:
1000개의 표본 분포

놀랍게도 정규 분포와 매우 유사한 모양을 보임 \(\rightarrow\) 표본을 많이 추출할수록, 표본 분포는 점점 더 정규 분포를 닮아감.
이 성질 덕분에 우리는 단 하나의 표본만으로도 “내 추정값이 얼마나 믿을 만한지”를 확률적으로 계산할 수 있음. → 신뢰구간(Confidence Interval)의 이론적 근거.
표본 크기의 역할
만약 표본 크기를 변경할 수 있고, 25, 50, 100 중에서 선택할 수 있다면?
여전히 목표가 그릇 속 초록색 파스타의 비율을 추정하는 것이라면, 어떤 크기의 삽을 선택하겠는가?
표본 크기의 역할
이전에 했던 작업을 다른 표본 크기에 대해서 반복해 보자.
각 표본 크기에 대해 1000개의 표본을 추출해 보자: \(n=25\), \(n=50\), \(n=100\).
rep_sample_n()함수를 다시 사용한다.
- 다양한 표본 크기의 생성
표본 크기의 역할

표본 크기와 표본 분포
표본 크기가 커질수록 표본 분포는 더 좁아진다.
즉, 표본 변동성에 의한 차이가 더 적어진다.
반복 횟수(여기서는 1000개)를 일정하게 유지하면, 더 큰 표본일수록 정규 분포에 더 가까워지고, 표준 편차가 더 작아진다.
표본 크기별 표준 편차 계산
| Sample Size | Standard Deviation |
|---|---|
| 25 | 0.10 |
| 50 | 0.07 |
| 100 | 0.05 |
표준 편차는 평균 주변의 분포의 확산 정도를 측정한다.
따라서 표본 크기가 증가하면, 전체 그린 파스타 비율에 대한 추정값이 더 정확해진다.
표본 추출 개념
추정을 목적으로 표본을 추출함.
전체 그린 파스타의 비율을 추정하기 위해 표본을 추출함.
표본 추출과 관련된 핵심 개념
표본 변동성이 추정값에 미치는 영향: 서로 다른 표본은 서로 다른 추정값을 제공함.
표본 크기가 표본 변동성에 미치는 영향: 표본 크기가 커질수록 추정값이 실제 값에 가까워짐.
표본 추출 용어 📖
모집단 (Population) 우리가 관심 있는 개체 또는 관측치의 전체 집합. \(N = 713\)개의 파스타.
모집단 모수 (Population Parameter) 모집단에 대한 알려지지 않은 수치적 요약값으로, 우리가 알고자 하는 값. 예: 모집단 평균 \((\mu)\), 그린 파스타의 비율 \((p)\).
전수 조사 (Census) 모집단의 모든 \(N\)개의 개체나 관측치를 철저하게 조사하여 모집단 모수 값을 정확하게 계산하는 방법.
표본 추출 (Sampling) 모집단의 크기 \(N\)에서 크기 \(n\)인 표본을 수집하는 과정.
점 추정량 (Point Estimate) 또는 표본 통계량 (Sample Statistic) 모집단의 알려지지 않은 모수를 추정하기 위해 표본에서 계산한 요약 통계량. 예: 표본 비율 \((\hat{p})\)은 모집단 비율 \(p\)의 추정값을 나타내며, “hat(모자)” 기호로 표시됨.
대표 표본 추출 (Representative Sampling) 표본이 모집단을 잘 대표하는가?
편향된 표본 추출 (Biased Sampling) 모든 파스타가 동일한 확률로 표본에 포함될 기회를 가졌는가?
무작위 표본 추출 (Random Sampling) 편향 없이 무작위로 표본을 선택하는 방식.
통계적 정의
우리는 계속해서 \(\hat{p}\)을 추정해 왔음.
표본 비율 \(\hat{p}\)의 표본 분포를 그려서 표본 변동성을 시각적으로 확인.
\(\hat{p}\)의 표본 분포의 표준 편차를 계산했음. 이 표준 편차는 특별한 이름을 가짐: 점 추정량 \(\hat{p}\)의 표준 오차 (Standard Error).
다시 아래 표 확인:
| 표본 크기 \((n)\) | \(\hat{p}\)의 표준 오차 |
|---|---|
| 25 | 0.10 |
| 50 | 0.07 |
| 100 | 0.05 |
- 핵심 요점: 표본 크기 \(n\)이 커질수록 점 추정량의 일반적인 오차 크기는 줄어듦.
- 이는 표준 오차(Standard error)를 통해 정량적으로 확인 가능.
표준 오차: 경영 의사결정에서의 의미
표준 오차(Standard Error)는 “내 추정값이 얼마나 불안정한가?”를 수치로 표현.
\[SE = \sqrt{\frac{p(1-p)}{n}} \quad \Rightarrow \quad n \uparrow \text{ 이면 } SE \downarrow\]
직관적 해석: 표본 크기를 4배 늘리면 표준 오차는 절반으로 줄어듦.
| 표본 크기 \((n)\) | 이론적 \(SE\) | 시뮬레이션 \(SE\) | 경영적 해석 |
|---|---|---|---|
| 25 | 0.100 | 0.098 | 추정 불확실성 높음 → 의사결정 리스크 ↑ |
| 50 | 0.071 | 0.068 | |
| 100 | 0.050 | 0.047 | 추정 불확실성 낮음 → 더 자신 있는 의사결정 |
트레이드오프: 표본을 크게 할수록 정확도는 올라가지만, 비용·시간도 증가함.
“얼마나 정확해야 충분한가?”가 경영 판단의 핵심.
전체 과정 정리
무작위 표본 (random samples)에서 얻은 점 추정량 (point estimates)은 모집단 모수 (population parameter)의 좋은 추측값을 제공함.
하지만 얼마나 좋은 추정값일까?
- 어떤 경우에는 \(\hat{p}\)가 \(p\)와 크게 다를 수도 있고, 어떤 경우에는 매우 가까울 수도 있음.
- 이러한 차이는 표본 변동성 (sampling variation) 때문임.
- 어떤 경우에는 \(\hat{p}\)가 \(p\)와 크게 다를 수도 있고, 어떤 경우에는 매우 가까울 수도 있음.
평균적으로 우리의 추정값은 정확할 것임. 이는 표본을 무작위로 추출하기 때문임.
- 즉, \(\hat{p}\)는 \(p\)의 불편 추정량 (unbiased estimator)이며, \(\mathop{\mathbb{E}}[\hat{p}] = p\) 임.
그렇다면, 전체 \(N=713\)개의 파스타 중 녹색 파스타의 실제 모집단 비율 \(p\)는 얼마일까?
- 그래프에 실제 모집단 비율 \(p=0.49\) 값을 추가.
불편성(Unbiasedness)과 표본 변동성(Sampling variation) 시각화

다양한 표본 추출 시나리오
| 시나리오 | 모집단 모수 | 기호 | 점 추정량 | 비즈니스 예시 |
|---|---|---|---|---|
| 1 | 모집단 비율 | \(p\) | 표본 비율 \(\widehat{p}\) | 신제품 구매 의향 비율 |
| 2 | 모집단 평균 | \(\mu\) | 표본 평균 \(\overline{x}\) | 고객 평균 구매액 |
| 3 | 비율 차이 | \(p_1 - p_2\) | \(\widehat{p}_1 - \widehat{p}_2\) | A/B 테스트 전환율 비교 |
| 4 | 평균 차이 | \(\mu_1 - \mu_2\) | \(\overline{x}_1 - \overline{x}_2\) | 처리군 vs. 대조군 매출 차이 |
| 5 | 회귀 계수 (기울기) | \(\beta_1\) | \(b_1\) 또는 \(\widehat{\beta}_1\) | 광고비 1원 증가 시 매출 변화 |
| 6 | 회귀 절편 | \(\beta_0\) | \(b_0\) 또는 \(\widehat{\beta}_0\) | 기본 수요 수준 |
중심극한정리 (Central Limit Theorem; CLT)
중심극한정리: 표본 크기가 커질수록, 표본 평균의 분포는 모집단의 분포 형태와 무관하게 정규 분포에 가까워진다.
핵심 조건
- 표본이 무작위로 추출될 것
- 표본 크기가 충분히 클 것 (\(n \geq 30\)이 통상 기준)
- 모집단 분포 형태는 무관 — 치우친 분포도 OK
경영적 의미
고객 구매액이 오른쪽으로 치우쳐 있어도,
표본 평균은 정규 분포처럼 행동함.
→ 신뢰구간·가설검정의 이론적 근거.

CLT: 파스타 실험과의 연결
파스타 실험에서 이미 CLT를 직접 목격했음.
- 파스타의 색상 비율 자체는 단순한 분포 (0 ~ 1).
- 그럼에도 1000번 반복 추출하면 → \(\hat{p}\)의 분포가 종 모양으로 수렴.
표본 크기 \(n\)이 커질수록 두 가지가 동시에 일어남:
| \(n = 25\) | \(n = 50\) | \(n = 100\) | |
|---|---|---|---|
| 분포 형태 | 종 모양 (약함) | 종 모양 (중간) | 종 모양 (뚜렷) |
| 표준 오차 \(SE\) | 0.098 | 0.068 | 0.047 |
| 추정 신뢰도 | 낮음 | 중간 | 높음 |
- Bottom line: 무작위 표본 + 충분한 \(n\) → 통계적 추론(신뢰구간, 가설검정)의 기반.
핵심 개념 요약 📋
| 개념 | 한 줄 정의 | 파스타 예시 |
|---|---|---|
| 모집단 (Population) | 알고 싶은 전체 대상 | 그릇 속 713개 파스타 전체 |
| 표본 (Sample) | 실제로 관측한 일부 | 손으로 꺼낸 50개 파스타 |
| 모집단 모수 (Parameter) | 전체의 진짜 값 (알 수 없음) | 실제 녹색 파스타 비율 \(p\) |
| 점 추정량 (Point Estimate) | 표본으로 계산한 추정값 | 표본 내 녹색 비율 \(\hat{p}\) |
| 불편 추정량 (Unbiased Estimator) | 평균적으로 틀리지 않는 추정 | 반복 추출 시 \(\hat{p}\)의 평균 \(= p\) |
| 표준 오차 (Standard Error) | 추정값의 불확실성 크기 | 표본 크기 ↑ → \(SE\) ↓ |
| 중심극한정리 (CLT) | 충분한 표본이면 분포가 정규화됨 | 1000번 추출 → 종 모양 히스토그램 |
Bottom line: 무작위 표본은 편향 없이 모집단을 대변하며, 표본이 클수록 더 믿을 수 있음.