Regression Inference
FMB819: R을 이용한 데이터분석
부트스트랩 분포
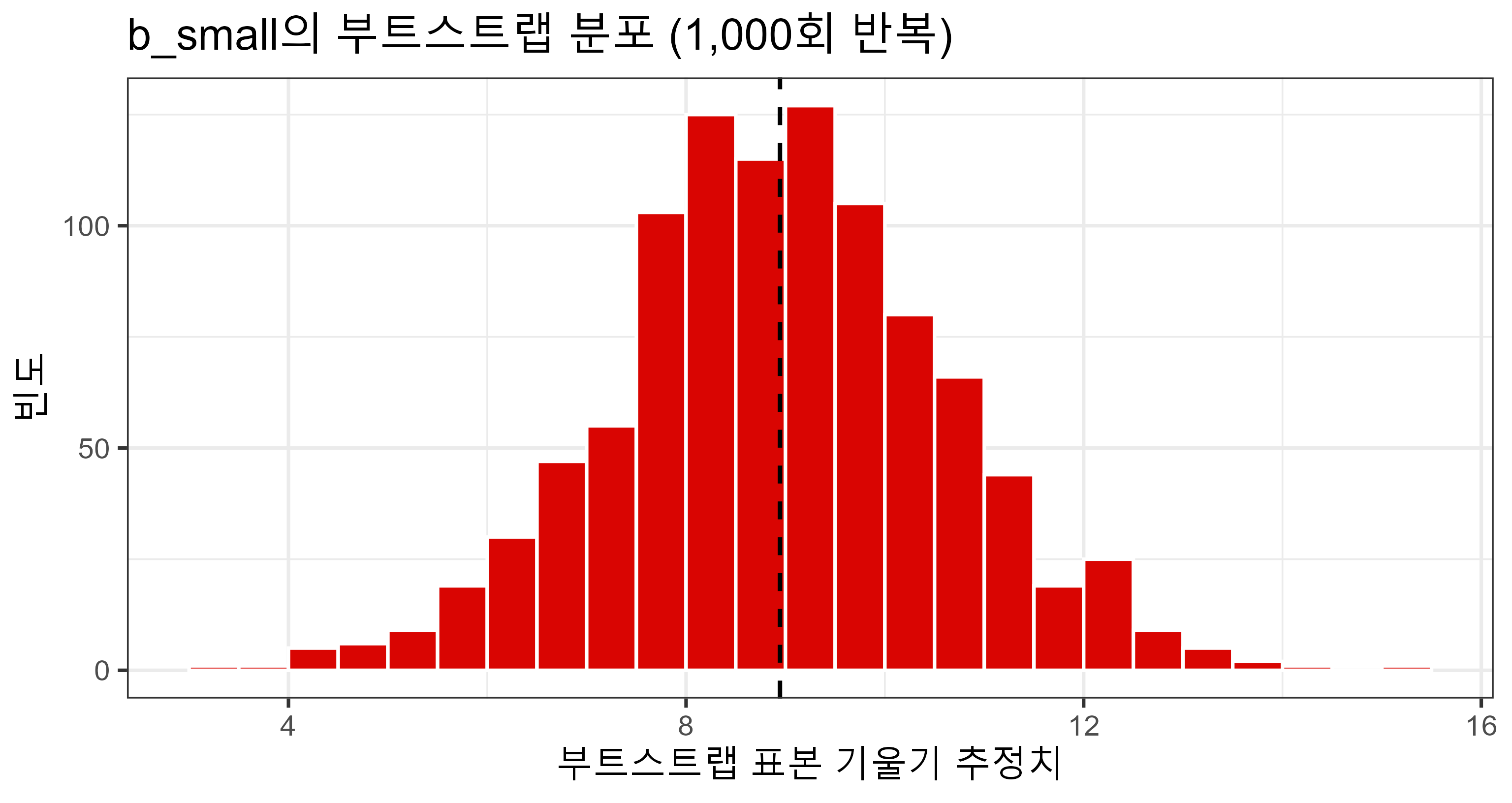
- 분포의 중심: 8.94 ← 원래 표본 \(b_\text{small}\)과 유사
- 분포의 표준 편차 = 표준 오차: 1.674 ← 테이블 값 1.68와 거의 일치
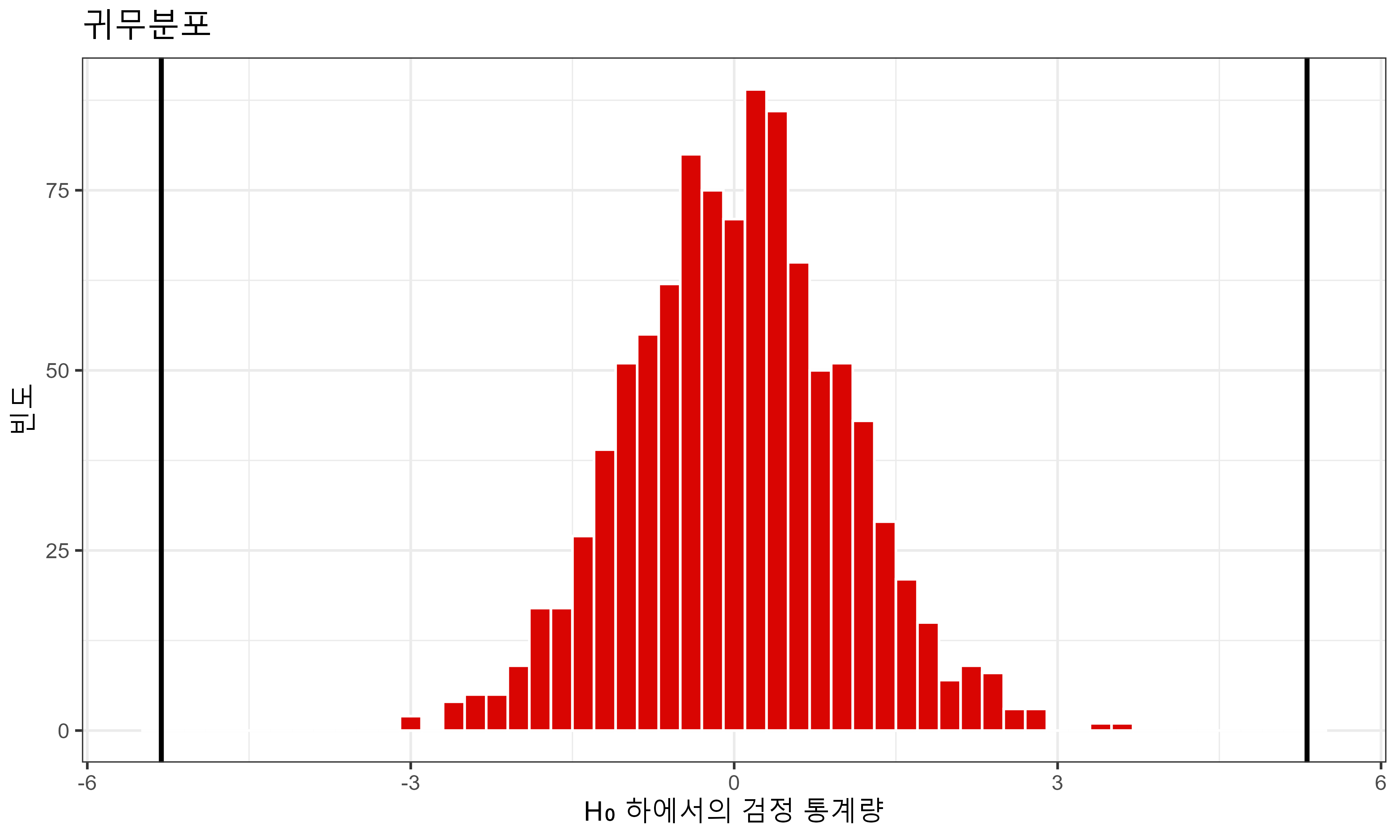
귀무분포와 p-값
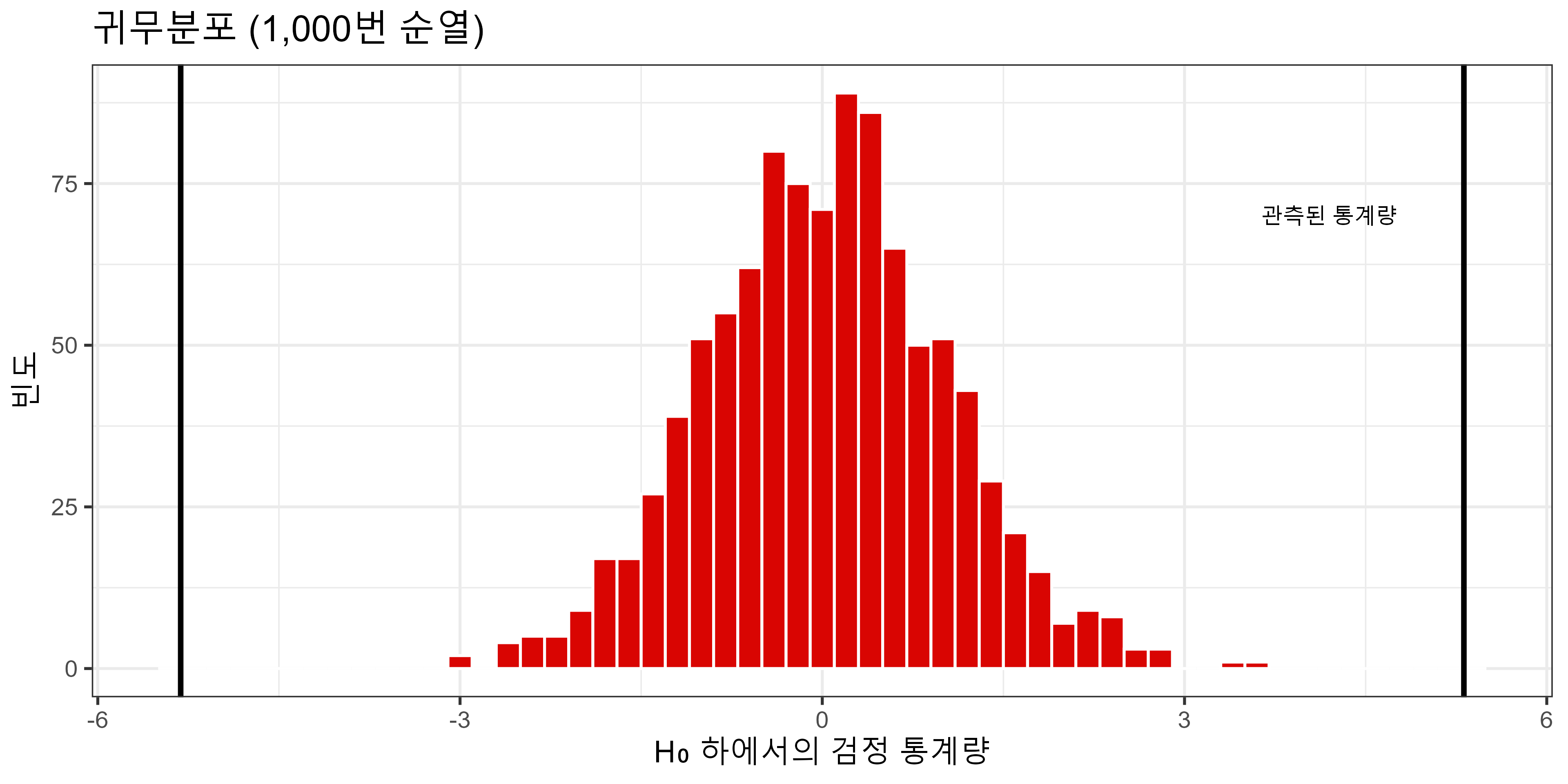
- p-값 ≈ 0: 어떤 유의수준 (\(\alpha\) = 0.1, 0.05, 0.01) 에서도 \(H_0\) 기각
- 즉, \(b_\text{small}\)은 통계적으로 유의하며, 소규모 학급이 수학 성취도에 실제 영향을 미침.
이론 기반 추론: 신뢰 구간
\(b_k\)의 표본 분포가 정규 분포를 따르므로, 95% 근사 규칙 적용:
\[\text{CI}_{95\%} = \left[b_k \pm 1.96 \times \hat{SE}(b_k)\right]\]
세 가지 방법 비교:
# A tibble: 1 × 3
term conf.low conf.high
<chr> <dbl> <dbl>
1 smallTRUE 5.60 12.2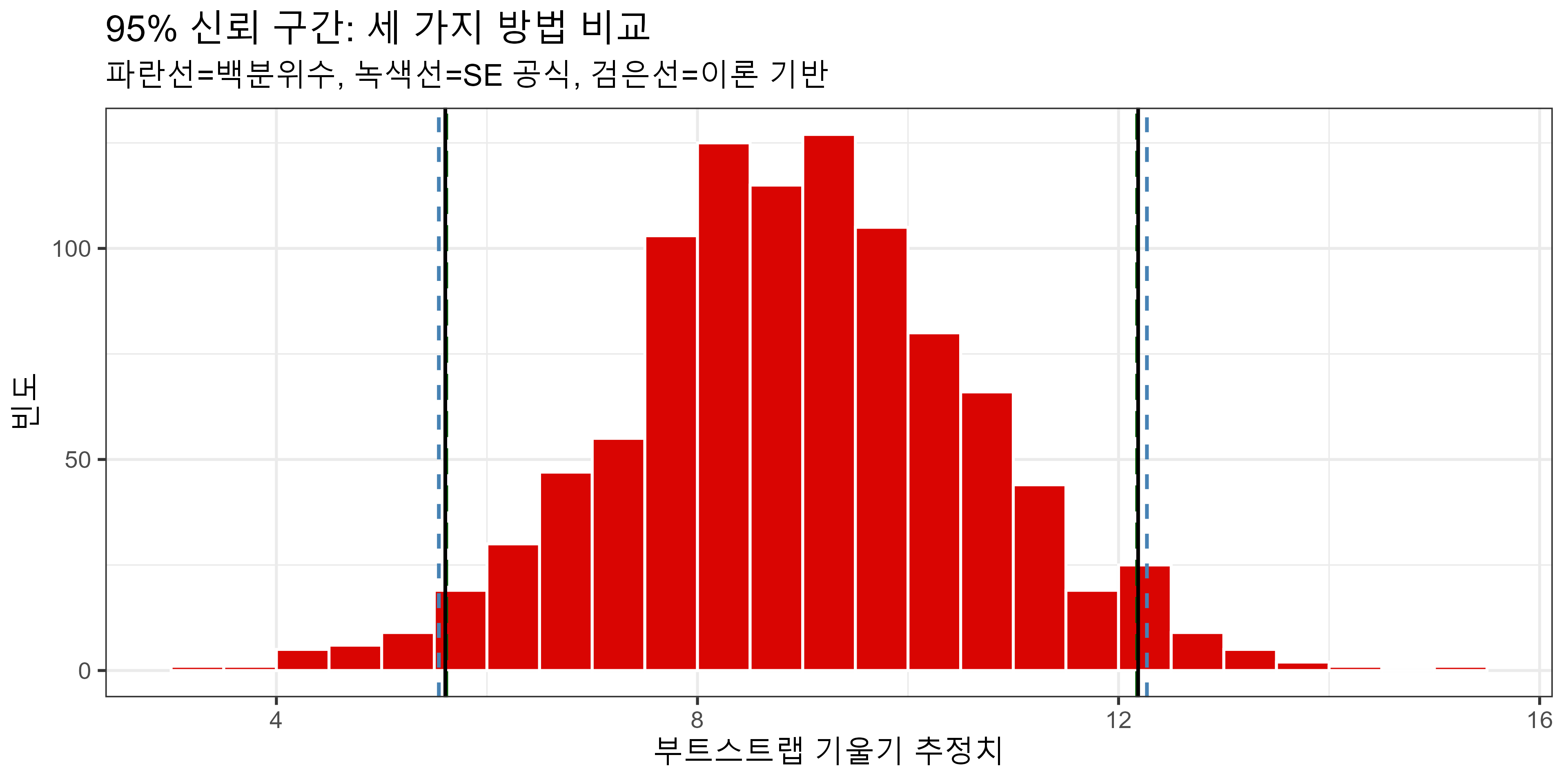
세 방법 모두 거의 유사한 구간을 산출함 → 이론·시뮬레이션이 수렴.
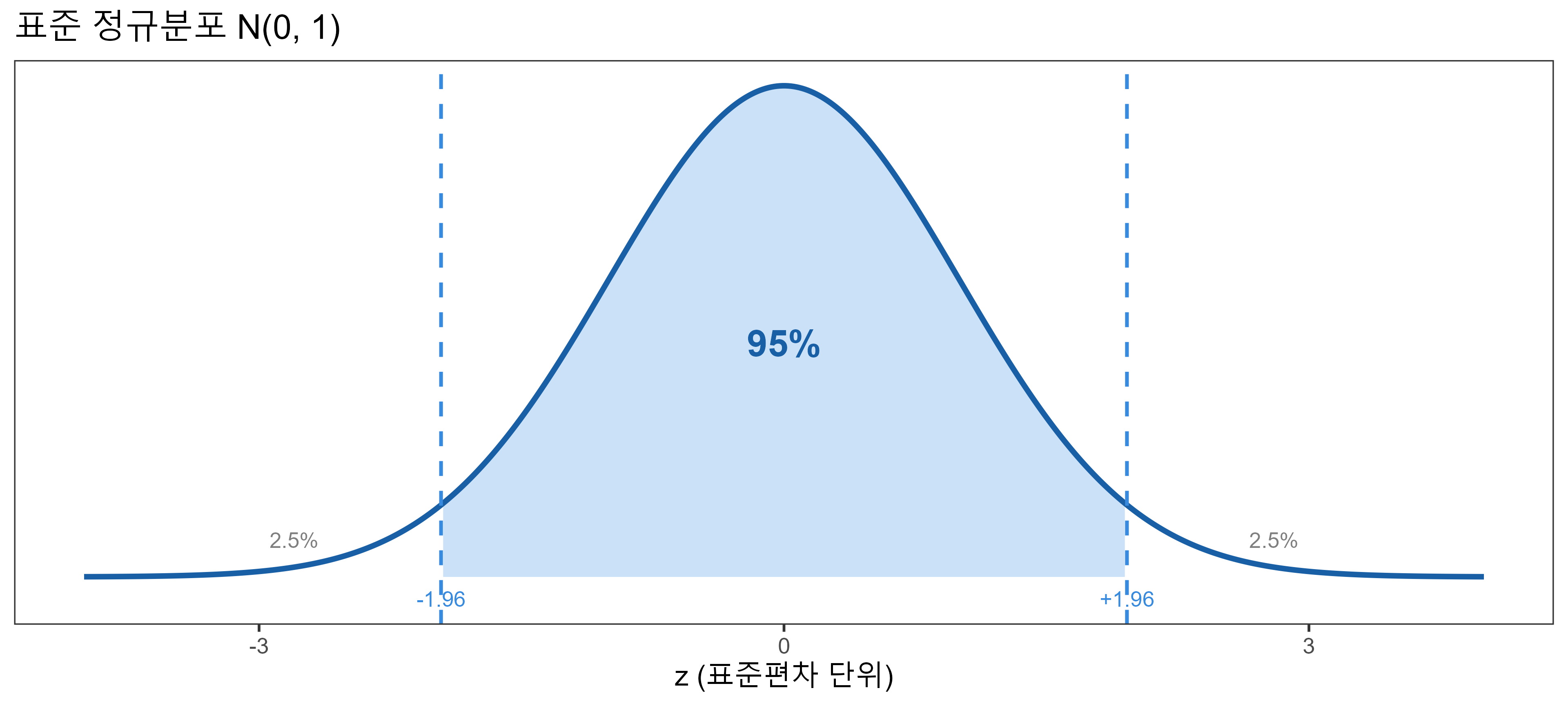
95% 신뢰 구간 공식: 1.96은 어디서 왔는가?
3단계 논리 흐름
① CLT 적용
표본이 충분히 크면, \(\hat{b}\)은 정규 분포를 따름:
\[b \approx N\!\left(\beta,\; SE^2\right)\]
② 표준화 (z-변환)
\[z = \frac{b - \beta}{SE} \approx N(0,\, 1)\]
③ 1.96의 출처
표준 정규분포의 성질:
\[P(-1.96 \leq z \leq +1.96) = 0.95\]
이를 \(\beta\)에 대해 풀면:
\[\therefore\quad b \pm 1.96 \times SE\]
신뢰수준별 z-값
| 신뢰수준 | z-값 | 구간 폭 |
|---|---|---|
| 90% | ±1.645 | 좁음 — 덜 보수적 |
| 95% | ±1.96 | 통상 사용 기준 |
| 99% | ±2.576 | 넓음 — 더 보수적 |
Task 2
- Task 1에서 생성한 부트스트랩 분포를 사용하여 백분위수 방법으로 95% 신뢰 구간을 계산하시오.
# A tibble: 1 × 2
lower upper
<dbl> <dbl>
1 5.54 12.3- 이전 슬라이드의 이론 기반 신뢰 구간과 얼마나 유사한가?
# A tibble: 1 × 2
lower upper
<dbl> <dbl>
1 5.61 12.2# A tibble: 1 × 3
term conf.low conf.high
<chr> <dbl> <dbl>
1 smallTRUE 5.60 12.2bootstrap_distrib %>%
ggplot(aes(x = stat)) +
geom_histogram(boundary = 9, binwidth = 0.5, col = "white", fill = "#d90502") +
labs(
x = "Bootstrap sample slope estimate",
y = "Frequency",
title = "95% confidence interval computed with different methods",
subtitle = "percentile (dashed), standard error (longdashed) and theory (solid)"
) +
geom_vline(xintercept = c(ci_pctile$lower, ci_pctile$upper), linetype = "dashed", show.legend = TRUE) +
geom_vline(xintercept = c(ci_stderror$lower, ci_stderror$upper), linetype = "longdash", show.legend = TRUE) +
geom_vline(xintercept = c(ci_theory$conf.low, ci_theory$conf.high)) +
theme_bw(base_size = 14)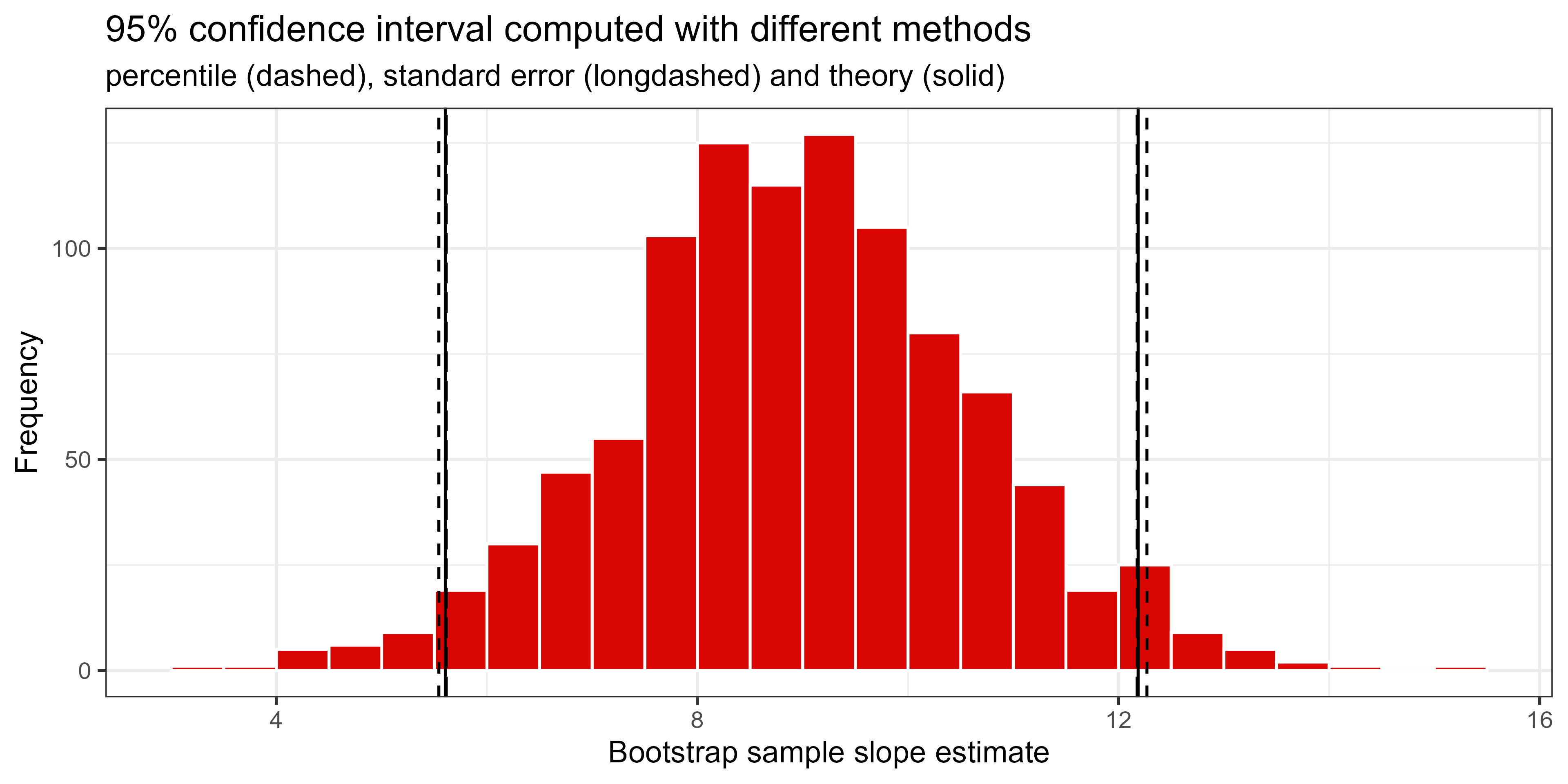
- 신뢰수준을 99%로 바꾸면 구간이 어떻게 달라지는가? 왜 그런가?
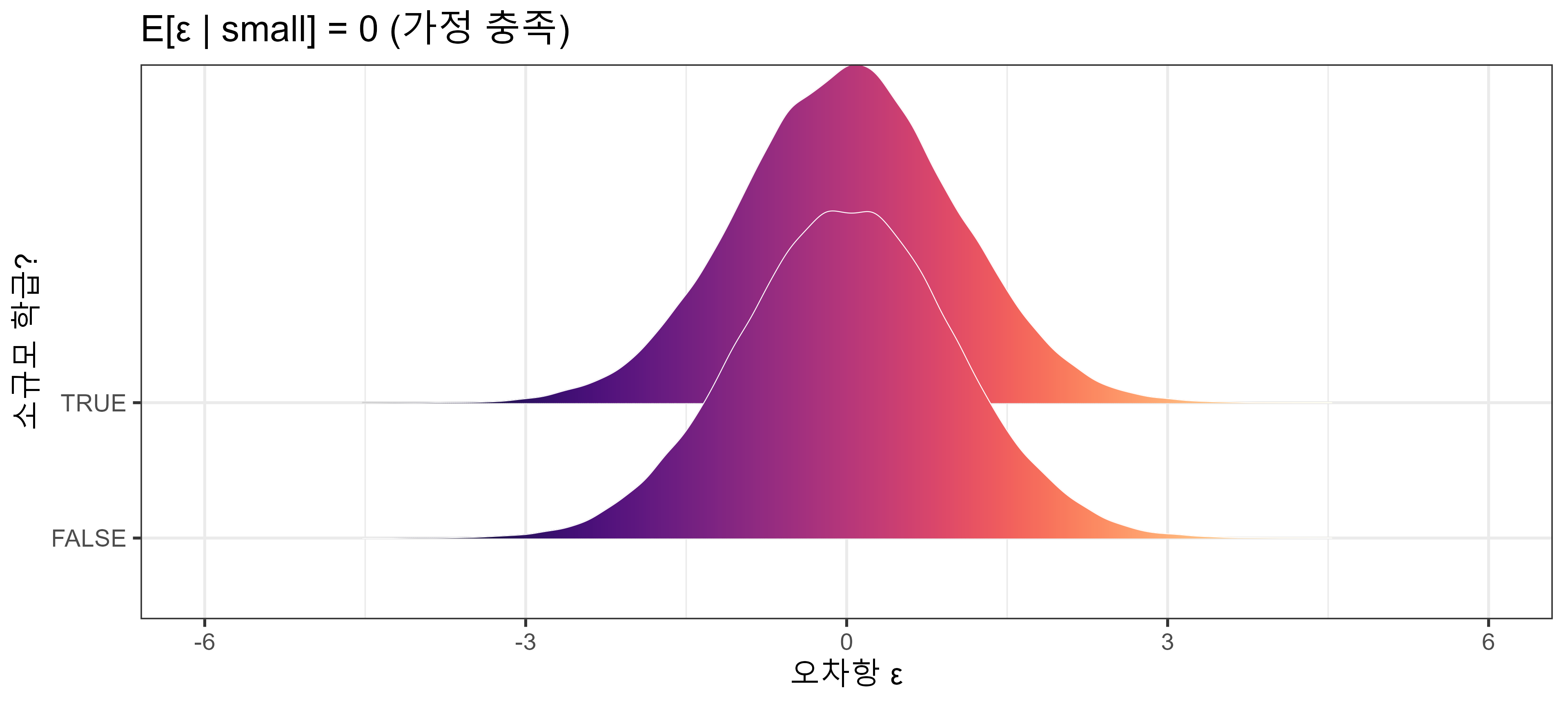
가정 ①: 외생성 (Exogeneity)
\[E[\varepsilon \mid x] = 0\]
오차항이 설명변수와 상관이 없어야 함 (Cov(ε, x) = 0).
가정 충족 (STAR 실험)
가정 위반 (관찰 연구)
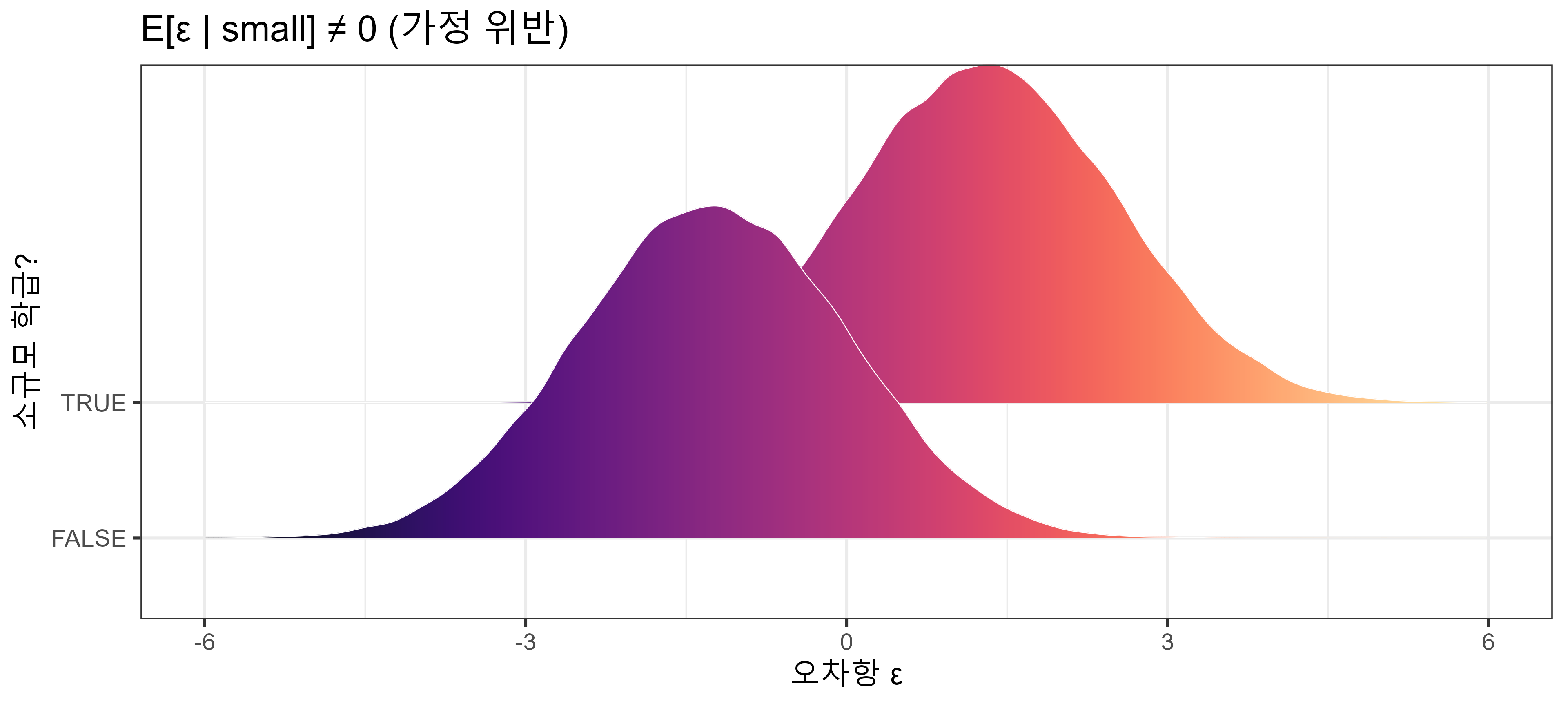
STAR가 무작위 배정 실험인 이유: 소규모 배정이 관찰되지 않은 요인(능력, 가정 환경)과 무관하도록 설계 → 외생성 보장.
불확실성 시각화: 100개의 부트스트랩 회귀선
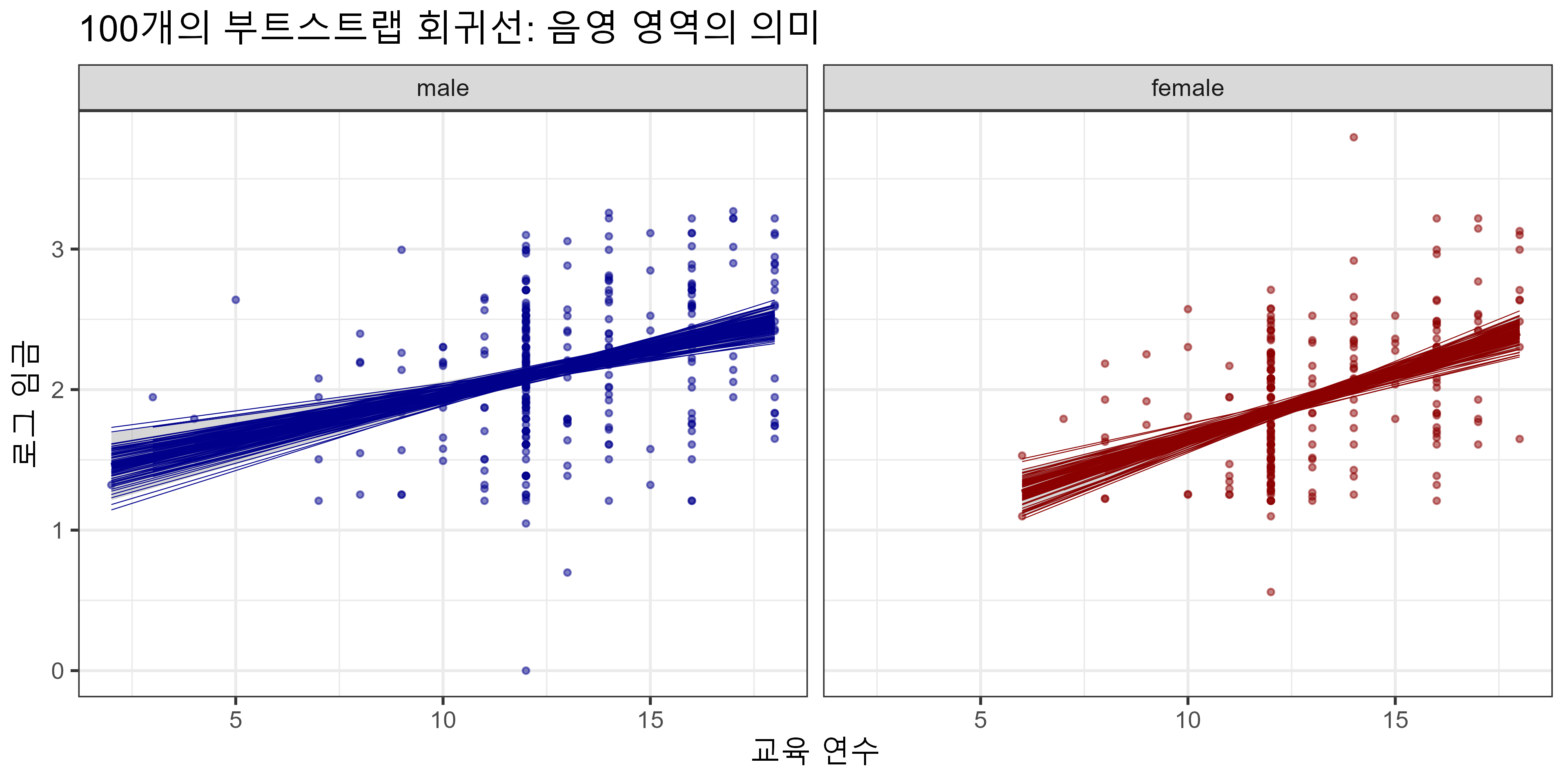
- 얇은 선 각각 = 하나의 부트스트랩 표본에서 얻은 회귀선
- 음영 영역 = 이 선들의 95%가 포함되는 범위 = 95% 신뢰 구간
Appendix: infer 파이프라인 전체 코드
# 부트스트랩 분포
bootstrap_distrib <- star_df %>%
mutate(small = as.numeric(small)) %>%
specify(formula = math ~ small) %>%
generate(reps = 1000, type = "bootstrap") %>%
calculate(stat = "slope")
# 귀무분포 (순열 검정)
null_distribution <- star_df %>%
mutate(small = as.numeric(small)) %>%
specify(formula = math ~ small) %>%
hypothesize(null = "independence") %>%
generate(reps = 1000, type = "permute") %>%
calculate(stat = "slope") %>%
mutate(test_stat = stat / sd(bootstrap_distrib$stat))
# p-값 계산
mean(abs(null_distribution$test_stat) >= observed_stat)