
FMB819: R을 이용한 데이터분석
Instrumental Variables
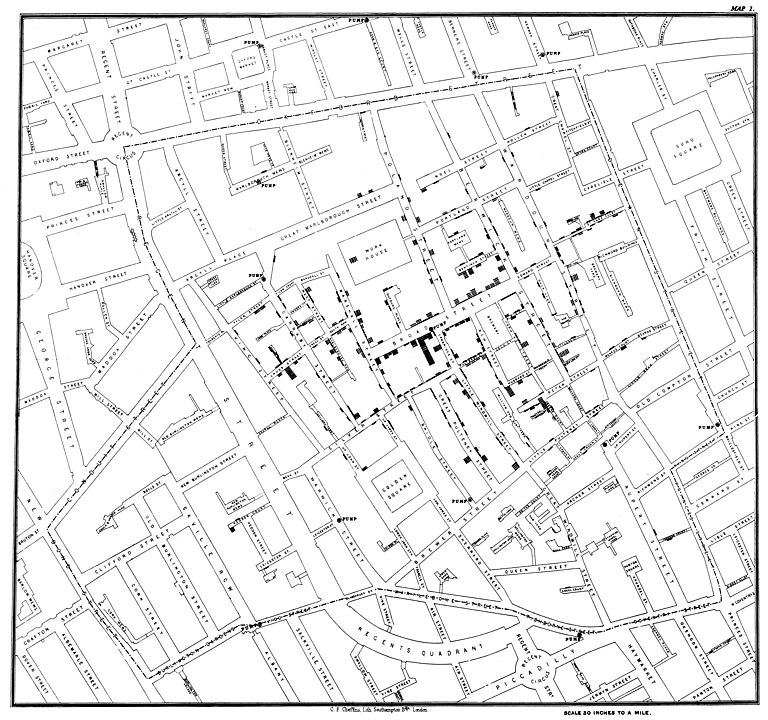
존 스노우의 (비)실험: 콜레라가 도시를 강타
존 스노우(John Snow)는 1850년경 런던에서 활동한 의사로, 그 당시 도시에서는 콜레라가 여러 차례 창궐하였음.
당시 질병의 전파 방식에 대한 논쟁이 있었음: 공기를 통해 전염되는가, 아니면 물을 통해 전염되는가?

스노우의 탐정 활동
스노우는 방대한 데이터를 수집하였음.
1854년 발생한 콜레라 유행 시 사망자의 위치를 지도에 표시하였음.
이 사건이 바로 악명 높은 브로드스트리트 펌프(Broadstreet Pump) 사건임.
cholera 패키지

cholera 패키지의 기능
- 또는 사례 번호 15번 환자의 이동 경로를 시각화할 수도 있음:

- 혹은 펌프 주변 지역의 보로노이 다각형(Voronoi polygons)을 추정할 수도 있음:

브로드 스트리트 펌프의 제거?
스노우는 브로드 스트리트 펌프(Broad Street Pump)가 원인이라고 지목함.
그는 펌프 손잡이를 제거할 것을 요청하였음.
하지만, 그는 이 조치가 유행병의 종식을 가져왔다는 점에 회의적이었음.

교육과 수입의 관계
학교 교육이 수입에 미치는 영향
- 학교 교육이 수입에 미치는 인과적 영향은 무엇일까?
- 제이콥 민서(Jacob Mincer)는 이 중요한 질문을 연구하였음.
- 그가 제안한 모델은 다음과 같음:
\[ \log Y_i = \alpha + \rho S_i + \beta_1 X_i + \beta_2 X_i^2 + e_i \]

교육과 수입의 관계 분석
\[ \log Y_i = \alpha + \rho S_i + \beta_1 X_i + \beta_2 X_i^2 + e_i \]
- 민서는 \(\rho\) 값이 약 0.11이라는 결과를 발견함.
- 이는 추가적인 1년의 교육이 약 11%의 수입 증가와 관련이 있음을 의미함.
- DAG(유향 인과 그래프)를 살펴보면, 이 모델이 적절한지 판단할 수 있음.
- 하지만 이 모델이 왜 문제가 있을 수 있는가?

민서의 모델과 관찰되지 않는 능력(Unobserved Ability)
- 사실 우리는 두 개의 관찰되지 않는 변수를 가지고 있음: \(e\) 와 \(A\).
- 물론 이를 구별할 수 없음.
- 따라서 새로운 관찰되지 않는 요인을 정의함: \[u_i = e_i + A_i\]

민서의 모델과 능력 편향의 영향
- 수식으로 표현하면: \[\log Y_i = \alpha + \rho S_i + \beta_1 X_i + \beta_2 X_i^2 + \underbrace{u_i}_{A_i + e_i}\]
- 때로는 이것이 중요하지 않으며 OLS의 편향이 작을 수 있음.
- 하지만 경우에 따라서는 상당한 영향을 미쳐 잘못된 결론을 내릴 수 있음. 예제 참고.

출생 분기와 임금 데이터
데이터를 불러오고 요약 정보 확인
| Unique | Missing Pct. | Mean | SD | Min | Median | Max | Histogram | |
|---|---|---|---|---|---|---|---|---|
| lnw | 26732 | 0 | 5.9 | 0.7 | -2.3 | 6.0 | 10.5 | 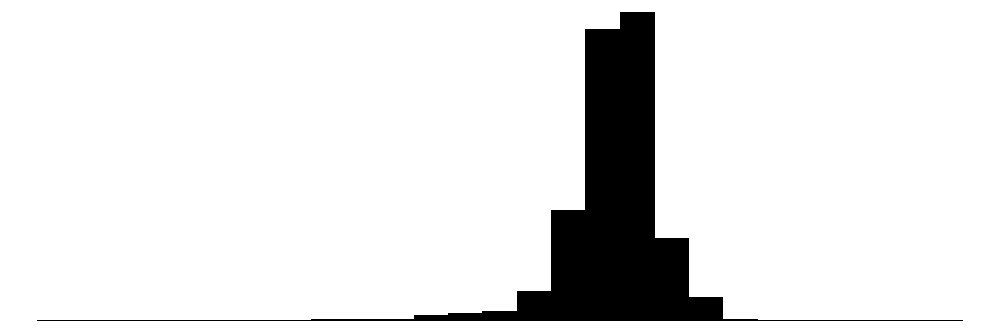 |
| s | 21 | 0 | 12.8 | 3.3 | 0.0 | 12.0 | 20.0 | 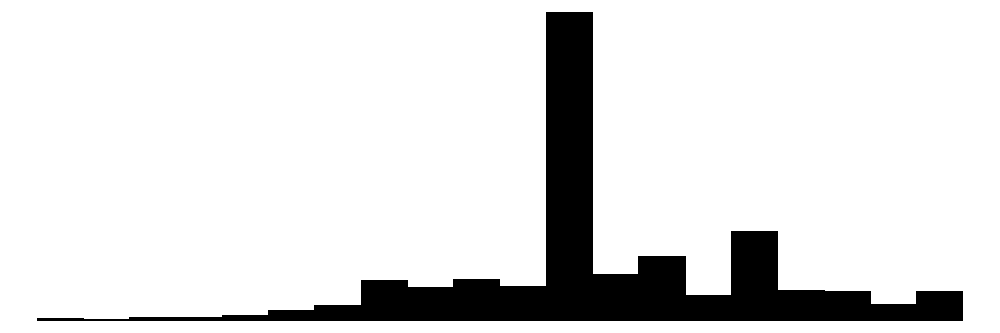 |
| yob | 10 | 0 | 1934.6 | 2.9 | 1930.0 | 1935.0 | 1939.0 | 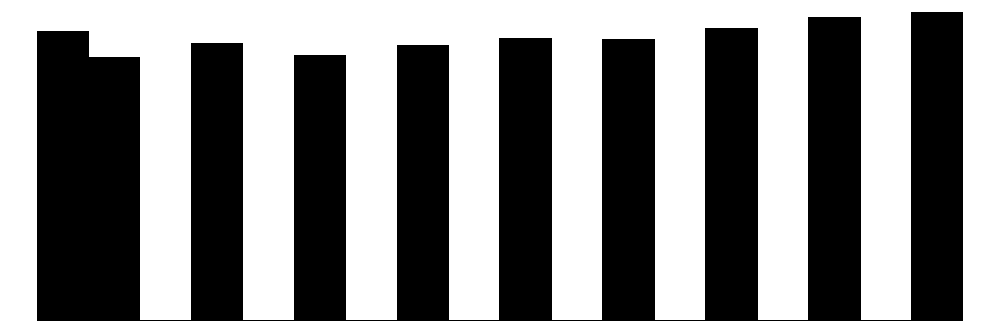 |
| qob | 4 | 0 | 2.5 | 1.1 | 1.0 | 3.0 | 4.0 |  |
| sob | 51 | 0 | 30.7 | 14.2 | 1.0 | 34.0 | 56.0 |  |
| age | 40 | 0 | 45.0 | 2.9 | 40.2 | 45.0 | 50.0 |  |
AK91 그림 1: 1단계 회귀 분석
- 숫자는 출생 분기별 평균 교육 연수를 나타냄.
- 4분기 출생자는 대부분 더 많은 교육을 받았음.
- 전반적으로 교육 수준은 증가하는 경향이 있음.

AK91 그림 2: 도구변수(IV)가 결과 변수에 미치는 영향
- 4분기 출생자가 전반적으로 더 높은 임금을 받음.
- 전체적으로 시간이 지나면서 주간 임금이 다소 감소하는 경향이 있음.

유효한 모델(A) vs 유효하지 않은 모델(B)

IV Standard Errors
