Confidence Intervals and Hypothesis Testing
FMB819: R을 이용한 데이터분석
부트스트랩 분포

- 부트스트랩 분포는 표본 분포를 근사하는 역할을 함.
- 분포의 중심은 원래 표본 \(\hat{p}\)에 가깝고, 퍼짐 정도가 추정의 불확실성을 나타냄.
부트스트랩 분포와 평균

- 부트스트랩 분포의 평균은 원래 표본 비율 \(\hat{p} = 0.46\)과 매우 가까움.
- 이제 이 분포에서 중앙 95%의 범위를 신뢰 구간으로 사용하자.
95% 신뢰 구간 시각화: 참값 포함 여부

- 붉은 영역이 95% 신뢰 구간. 실제 모집단 비율 \(p\)가 구간 내에 포함됨.
- 항상 포함될까? 다음 슬라이드에서 확인.
신뢰 구간의 올바른 해석

100개의 신뢰 구간 중 약 95개가 실제 모수 \(p\)를 포함함.
차별의 증거가 있는가?
성별별 승진 결정 집계
# A tibble: 4 × 4
# Groups: gender [2]
gender decision n percentage
<fct> <fct> <int> <dbl>
1 male not 3 12.5
2 male promoted 21 87.5
3 female not 10 41.7
4 female promoted 14 58.3- 남성 승진율: 87.5%, 여성 승진율: 58.3%
- 차이: 29.2%포인트

핵심 질문: 이 29.2%p 차이가 성차별의 증거인가, 아니면 우연히 발생한 것인가?
귀무분포 생성: 1,000번의 무작위 재배열

- 분포의 중심은 0 근처: 성차별이 없으면 차이가 0에 가까워야 함.
- 실제 관측값 0.292는 분포의 오른쪽 끝에 위치 → 매우 드문 값.
p-값 시각화

- 파란 영역 = p-값: \(H_0\) 하에서 0.292 이상의 차이가 나올 확률.
검정 오류 (Testing Errors)
- 확률을 다루기 때문에 오류를 피할 수 없음.
- 0.292의 차이는 \(H_0\) 하에서 드물지만 불가능하지는 않음.
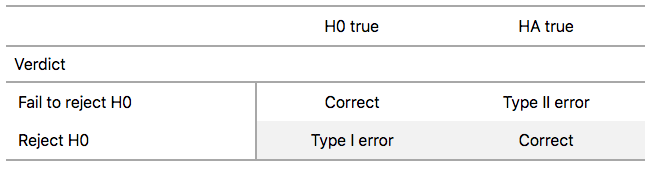
제1종 오류 (Type I Error)
\(H_0\)이 참인데 기각 → False Positive
예: 실제로 차별이 없는데 “있다”고 결론
유의수준 \(\alpha\)로 제어: \(\alpha = 0.05\)이면
5% 이하의 확률로만 이 오류를 범함.
제2종 오류 (Type II Error)
\(H_0\)이 거짓인데 기각 못함 → False Negative
예: 실제 차별이 있는데 “없다”고 결론
Appendix: infer 파이프라인 전체 코드
# 귀무분포 생성
null_distribution <- promotions %>%
# 변수와 성공 기준 지정
specify(formula = decision ~ gender,
success = "promoted") %>%
# 귀무가설: 성별과 승진 독립
hypothesize(null = "independence") %>%
# 1,000번 무작위 재배열
generate(reps = 1000, type = "permute") %>%
# 각 재배열에서 p_m - p_f 계산
calculate(stat = "diff in props",
order = c("male", "female"))
# 귀무분포 시각화
visualize(null_distribution,
bins = 10,
fill = "#d90502") +
labs(x = "Difference in promotion rates (male - female)",
y = "Frequency") +
xlim(-0.4, 0.4) +
theme_bw(base_size = 14)